The crappy software cycle
2023-04-08
What is good or bad code is very subjective. It’s easy to spot terrible code. For example, a function copied and pasted 20 times having nothing but a string constant modified in each copy is hopefully universally bad code. A 1000-line of code function should be classified the same way. However, once you get past the extremes of bad code, it becomes a matter of personal preference. While I may prefer to do things in some way and you may prefer to do them in another, this doesn’t mean one of them is better than the other.
A lot of times you can’t make that decision by looking at a piece of code in isolation. The context in which a piece of code was architected around matters. Abstractions are great when they’re needed, but introducing them when they’re not can turn simple code into a jigsaw puzzle where you need to understand too many pieces to figure out what’s going on.
Letting abstractions grow naturally
Abstractions are necessary as your codebase grows. Having no abstractions at all means you’ll have lots of duplicated pieces of code, and it will become hard to understand what the code is doing. Imagine a 1000 lines of code function; it’s really hard to understand the full scope of what’s going on without reading the entirety of it. On the other hand, adding too many layers of abstraction can lead to a similar issue, where there’s so much hidden complexity that it’s hard to understand what exactly is going on. None of these extremes is a place you want your codebase to be in.
Trying to organize the code before you write it can not only be pretty hard but it can also easily backfire. When doing this, you will typically architect it in such a way as to be able to accommodate future changes. You sort of know what your code will need to do in the future, but trying to predict this accurately and making decisions based on this too early can cause some problems given:
- What you think you’ll need is not necessarily set in stone. The product may pivot, or priorities may change. That thing that you’re planning on implementing in 2 months may end up happening a year from now, or it may not even happen at all.
- By the time you get to the change that you supposedly knew you’d make, enough has changed in the codebase that what you originally architected doesn’t fit anymore. This plays great with the point above: you thought you’d do this very soon, turns out priorities changed, you added a bunch of other features and by the time you get there, you realize you need to re-architect everything to be able to implement it.
Because of this, it’s a good idea to start simple and let abstractions grow naturally. Don’t add more abstractions than you need; don’t overengineer your code to handle all possible situations. Start simple and only add the abstractions you need along the way to make your code easy to understand and test.
No architecting at all?
Letting abstractions grow naturally doesn’t mean that you’re not going to spend any time at all thinking about how to structure your code. You should have a rough idea of where the code is going so as not to write some and almost immediately throw it away. For example, if you’re currently working on adding a feature, think for a few minutes about what the implications of that are rather than jumping in and implementing it right away.
The takeaway should be that you should think enough to know how you’re going to implement what you’re doing now, but not too much to have a plan on how it will keep evolving.
The crappy software cycle
If you take the route above, your code will be simple for a while until it won’t be anymore. At some point what you initially did doesn’t work anymore and it will be time to clean it up. You’ll find yourself fighting with the code, where trying to add something simple becomes a pain. At that point (ideally before it’s too painful), you should perform an iteration to clean it up. You then continue adding code until you feel the pain again, so you perform another cleanup. You can think of this as a crappy software cycle:
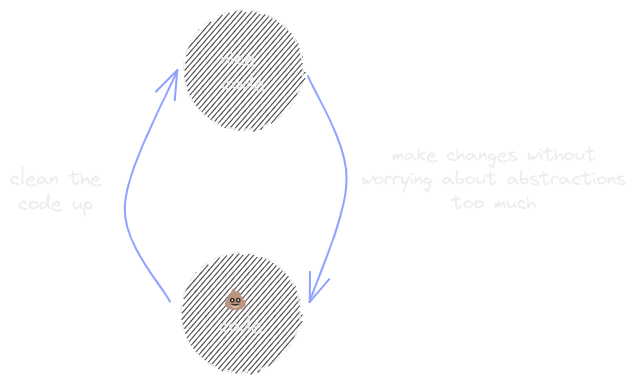
You start with no code. You start making changes until at some point that grows beyond what you planned for. You clean it up and have nice code as a result. Rinse and repeat. The cleanups don’t need to involve the entire codebase or even large pieces of code. Sometimes there are small bits that outgrow themselves and need to be simplified.
I think this is a great approach to building software for various reasons.
Complex code is complex
As codebases grow, it is natural that eventually, they become fairly complex. You may have many thousands or even millions of lines of code that you’ve been piling up for years. At some point in your codebase’s journey, complexity is necessary. You can’t deal with that amount of code without having abstractions in place to protect you from loading too much of that code’s context into your brain for every change you make.
However, you don’t want that complexity until you need it. Otherwise what could be a tiny code change becomes a huge burden because of the way the code is structured, forcing you to re-think your approach because the simple solution just doesn’t fit. You don’t want to be in that state too early, or otherwise, every change you make becomes a nightmare.
By introducing and dealing with complexity in an iterative approach you manage to only deal with the complexity you need today. Making changes becomes easier because there are fewer layers of abstractions and new layers are only created as needed.
Avoiding incorrect abstractions
Trying to architect your code too early can result in the wrong abstractions being created. You may think that you need to do things in a certain way but forgot about particular details that invalidate your strategy. It’s simply not possible to preemptively architect your code to take 100% of the future changes into account so you’re bound to make incorrect decisions. Taking things one step at a time prevents this and lets you build the abstractions that you need today for the code you already have or are currently writing.
Repeating patterns
Unless you’re jumping into an entirely new codebase using a new language or framework, the code you write will typically not look much different from what you’ve written before. This makes it easier to come up with reasonable code without planning too much, given you’ll likely follow a pattern you’ve used before. You will often encounter the same types of code smells and tackle them in similar ways.
Gotchas
While I think this iterative approach works great, it may not be for everyone.
Being disciplined
I think the main drawback is you need to be very disciplined. You need to be able to detect when the code has outgrown itself and bite the refactoring-bullet. It’s easy to get used to the way the code is structured and keep making it crappier without ever cleaning it up, which leads to a mess.
Detecting when the codebase needs a round of cleanup comes in many forms. I think it often comes from just extending what the code is already doing but this time it just feels like it went too far. For example:
- You copy/paste a chunk of code because there are already a couple of places around that are already doing the same. Sometimes copy/pasting 2 or 3 lines of code is fine. But when you find yourself doing that repeatedly, it’s time to introduce an abstraction.
- You add code to handle yet another condition in some function and realize there’s now really too much going on in it.
- More generically though, you write some code following the structure it currently has and something just feels off.
Culture
This requires the team/company culture to accept the fact that you will spend time iterating on the code itself. Sometimes a small change will take a small amount of time, while others may make the codebase cross the crappy code threshold and will require a bit more time to accommodate for the cleanup. This needs to be accepted and be part of the way the team works.
While agile methodologies try to iterate quickly and would seem to be aligned with this approach (especially via something like Emergent Design), they don’t necessarily fit it that well. The need to structure iterations into sprints with a must-be-completed set of tasks means you may not be able to spend the necessary time you need to clean things up as you go. Of course, there’s various flavors of agile so this may work for you.
You can’t operate this way
I think writing code without spending much time thinking about its structure ahead of time only really works if you’ve read and written your fair share of code. On a similar line, if you haven’t been writing software for long, odds are this less-structured approach will result in not-so-great code. This is why this approach may not be well suited for junior people, who typically will need some mentorship before being able to produce higher-quality code.
Some other people, even if they have their fair share of experience, may just need a more structured approach and that’s okay. Sometimes it’s hard to come up with decent code without spending some time thinking about it.
Conclusion
Writing code in an iterative cycle that includes the necessary cleanups is a great way to write software. You spend less time thinking of what the code will eventually do, which is likely wrong and instead focus on what it needs to accomplish today. The more you write code, the easier it becomes to write reasonable code without spending too long designing it. I think this provides a good trade-off between the time spent creating code and the quality of it.