Catching null pointer exceptions
2023-03-03
A while back, we had a situation at work where a customer hit a bug that materialized as an issue popping up in sentry on our end. This wasn’t uncommon but the troubleshooting for this one bug was memorable. The conversation that popped up on slack after we received the sentry notification about it went something along the following lines:
Bob: Looks like the issue is that a
PurchasedProduct’sdate_purchasedattribute isnulland we’re not handling that case, so it’s blowing up. We should add a check for it.Mike: Got it, on it.
A few minutes later a pull request is up, which is going to be merged soon as soon as the CI pipeline is green…
Me: Hol’ up. What do you mean the
date_purchasedisnull? That sounds… Suspicious? This must be a required attribute.Bob: Huh, let me see…
Soon after, an engineer that’s touched that part of the code more than my team joins the conversation:
Jane: Those
PurchasedProductobjects are getting materialized from that other table in this context, and the materialization is not setting thedate_purchasedproperty because up to now it wasn’t needed.
So we proceed to fix the issue, which was the fact that the required field should have been materialized as well but wasn’t. Without a second look, we would have added a bogus condition which, while it would have fixed the symptom of the issue, wouldn’t have fixed the underlying root cause.
Root cause vs observable behavior
The attempt to “catch the null pointer exception” is an attempt to fix the observable behavior rather than the root cause of the bug. Issues usually materialize in some way but the root cause is often hidden behind one or more layers:
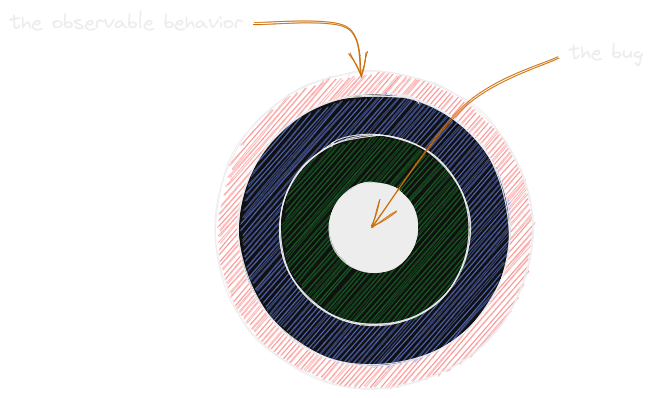
For example:
- In this case, the attribute should be present but isn’t. The issue is not that the attribute is absent (we need to handle it being absent!) but why it’s absent instead.
- A service hit its configured k8s memory limit and was restarted. The issue is not that we hit the limit (we need to increase the limit!) but why we ran out of memory in the first place.
- An element in some
List<Integer>wasnulland it caused that function to explode. The issue is not that that function can’t handlenullelements (let’s filternulls out!) but rather how theListhappened to have anullin it in the first place.
The problem with all of these examples is that the focus is being put in the wrong place. The bug is not what we observed but instead the underlying problem that caused it to be occur and be noticed in the first place.
Finding root causes
When a problem pops up, we need to “peel the problem onion” until we reach its core: the root cause. This is what the 5 whys technique achieves by asking the same “why?” question 5 times, each time getting deeper and deeper into what the problem’s cause really is.
The way I like to think about chasing down root causes is that you’re building upon assumptions. When you start looking at an issue, there’s an entire universe of potential root causes, none of which you have yet excluded. As you start digging into it, you realize that an entire category of root causes can’t be possible because certain conditions were met. For example, you check the logs and you realize that that database lookup was successful so the root cause can’t be that it could not be found, or that the database was down, etc. In a way, you’re slicing some of the possible root causes away with every discovery you make. These discoveries become assumptions about the state of the system when the issue occurred.

As you build your assumptions, you narrow down what the problem could be until eventually you’re left with the root cause. In a way you’re trying to corner the issue by excluding every other possibility.
Coming up with assumptions
Assumptions usually come from hunches, either because you’ve seen a similar issue before or because the problem kind of smells like that thing happened. You then proceed to verify whether the hunch was accurate and build on top of it:
- If you were right, you’ve taken the entire universe of possible root causes and zoomed into a specific section of it, effectively ignoring the rest of them. This is what you’d hope for since it greatly narrows down the list of possible root causes.
- If you were wrong, this is not as useful but it still is helpful: you can now assume that that thing did not happen and therefore all those other root causes can’t be the issue.
As you keep validating your hunches, you zoom in and slice away pieces of the root cause universe one assumption at a time, making it easier to diagnose the root cause.
Wrong assumptions
Sometimes as you’re building your assumptions you re-evaluate what you know so far and realize you made a mistake, possibly in the form of a contradiction (e.g. that happened but also didn’t), which means one or more of your assumptions are wrong. Because you build assumptions on top of each other, if you made a mistake and incorrectly assumed that thing either happened or it didn’t, likely, a lot of the assumptions you built on top of that were false.
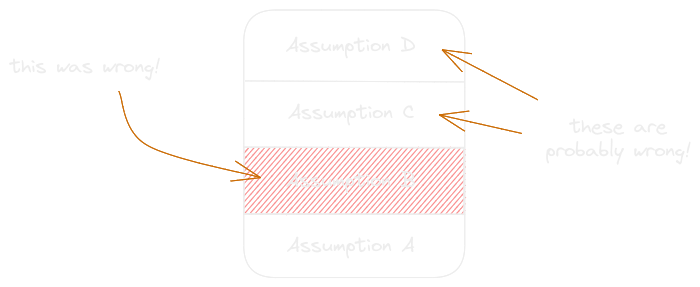
This sucks but it’s okay, you can re-evaluate every assumption you made on top of it and figure out whether they’re still valid.
Being methodical
Your search for a root cause will typically be similar depending on the environment and tools you’re using, so it’s usually a good idea to have a checklist, either in your brain or written somewhere, to be followed whenever something breaks. This is very dependent on each system but it can typically involve:
- Checking metrics/dashboards to check what went wrong around the time the issue popped up or even sometime before it did. It’s always good to establish baselines as zooming into the issue’s time range too quickly may make you ignore periodic patterns, a trend, etc.
- Check logs to figure out specifics about the issue. Metrics are great to get a high-level overview of what happened but logs should give you way more fine-grained and hopefully useful information.
- Once you have a general idea of what the issue was, try to reproduce it locally. Writing a test is the perfect way to do this: you not only get to validate your assumptions in the form of code but once you’re done you also automatically have a way to make sure your solution fixes the issue. Avoid writing a fix without a unit test. This may sound obvious but a lot of times you say “eureka!” and change something, only to find it didn’t really fix anything. You should be testing your code anyway (right?) so you’ll need that test as part of your change; take that as an opportunity to write the test first and only try to fix the issue once you have it.
- Depending on the magnitude of the issue, it’s a good idea to start writing down your assumptions. In general, I like to keep them in my mind but at some point, they can start getting overwhelming so writing them down can help. You may also need more than a day to fix the issue and you don’t want to wake up tomorrow and realize you forgot whether that thing was true or not.
Conclusion
While it is tempting to focus on fixing the observable symptoms of a bug, it is important to dig deeper and identify the root cause to effectively address the issue. This can be done by building assumptions on top of each other and slowly peeling the “problem onion” until the underlying root cause is found. Remember to write tests so you can verify your assumptions and ensure your fix does the right thing!